- چگونه از ارزهای دیجیتال درآمد کسب کنیم؟
- محافظت از قیمت و کدام کارتهای اعتباری آن چیست؟
- تجزیه و تحلیل قیمت مونرو: XMR با 226. 8 دلار صعود می کند. تصحیح برای دنبال کردن؟
- بازار سهام امروز: آسیا با وجود داده های رشد چین مخلوط شده است
- این معیار کلیدی قیمت اتریوم نشان می دهد که معامله گران ETH آنقدر که به نظر می رسد نزولی نیستند
- پیش نویس مسخره NY Jets: اطراف QB آرون راجرز با استعداد
- عملکرد مقدار جستجوی Power BI 101: نحو و استفاده ساده شده
- راهنمای معاملات روز برای امروز: پنج سهام خرید یا فروش برای جمعه - 2 ژوئن
- شاخص های فنی برای مبتدیان
- نشانگر توقف دنباله دار برای معامله

آخرین مطالب
امکانات وب



ایندکس ها برای سرعت بخشیدن به فرآیند پرس و جو در SQL Server استفاده می شوند و در نتیجه عملکرد بالایی دارند. آنها شبیه به شاخص های کتاب درسی هستند. در کتابهای درسی ، اگر نیاز به یک فصل خاص دارید ، به فهرست می روید ، شماره صفحه فصل را پیدا کرده و مستقیماً به آن صفحه بروید. بدون فهرست ، روند یافتن فصل مورد نظر شما بسیار کند خواهد بود.
همین مورد در مورد فهرست ها در پایگاه داده ها نیز صدق می کند. بدون فهرست ، DBMS برای بازیابی نتایج مورد نظر باید تمام سوابق موجود در جدول را طی کند. این فرآیند اسکن جدول نامیده می شود و بسیار کند است. از طرف دیگر ، اگر شاخص ها را ایجاد کنید ، پایگاه داده ابتدا به آن فهرست می رود و سپس سوابق جدول مربوطه را مستقیماً بازیابی می کند.
دو نوع شاخص در SQL Server وجود دارد:
- شاخص خوشه دار
- شاخص غیر خوشه
شاخص خوشه دار
یک شاخص خوشه ای ترتیب را تعریف می کند که در آن داده ها از نظر جسمی در یک جدول ذخیره می شوند. داده های جدول را می توان فقط به روش مرتب کرد ، بنابراین ، فقط یک شاخص خوشه ای در هر جدول وجود دارد. در SQL Server ، محدودیت اصلی اصلی به طور خودکار یک شاخص خوشه ای در آن ستون خاص ایجاد می کند.
بیا یک نگاهی بیندازیم. ابتدا با اجرای اسکریپت زیر یک جدول "دانشجویی" در داخل "Schooldb" ایجاد کنید ، یا اطمینان حاصل کنید که در صورت استفاده از داده های زنده خود ، از پایگاه داده شما کاملاً پشتیبان تهیه شده است:
در جدول "دانشجویی" توجه داشته باشید که ما محدودیت اصلی اصلی را در ستون "ID" تعیین کرده ایم. این به طور خودکار یک شاخص خوشه ای در ستون "ID" ایجاد می کند. برای دیدن تمام شاخص ها در یک جدول خاص ، روش ذخیره شده "SP_HELPINDEX" را اجرا کنید. این روش ذخیره شده نام جدول را به عنوان یک پارامتر می پذیرد و تمام شاخص های جدول را بازیابی می کند. پرس و جو زیر شاخص های ایجاد شده در جدول دانشجویی را بازیابی می کند.
پرس و جو فوق این نتیجه را برمی گرداند:
| index_name | index_description | index_keys |
| pk__student__3213e83f7f60ed59 | کلید اصلی خوشه ای ، منحصر به فرد واقع در ابتدا | id |
در خروجی می توانید تنها یک فهرست را مشاهده کنید. این شاخصی است که به دلیل محدودیت اصلی اصلی در ستون "ID" به طور خودکار ایجاد شده است.
Another way to view table indexes is by going to “Object Explorer> Databases> Database_Name> Tables> Table_Name>ایندکس ها ". برای مرجع به تصویر زیر نگاه کنید.
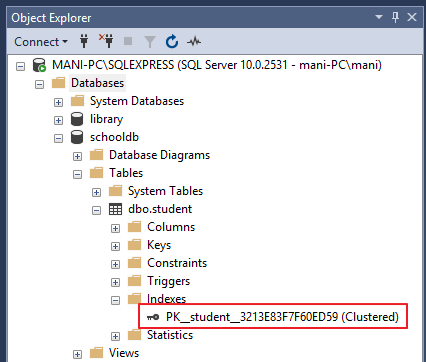
این شاخص خوشه ای رکورد را در جدول دانشجویی به ترتیب صعودی "شناسه" ذخیره می کند. بنابراین ، اگر رکورد درج شده دارای شناسه 5 باشد ، رکورد به جای ردیف اول در ردیف 5 جدول وارد می شود. به همین ترتیب ، اگر رکورد چهارم دارای شناسه 3 باشد ، به جای ردیف چهارم در ردیف سوم قرار می گیرد. این امر به این دلیل است که شاخص خوشه ای باید ترتیب فیزیکی سوابق ذخیره شده را با توجه به ستون فهرست بندی شده یعنی ID حفظ کند. برای دیدن این سفارش در عمل ، فیلمنامه زیر را اجرا کنید:
فیلمنامه فوق ده رکورد را در جدول دانشجویی وارد می کند. توجه کنید که سوابق به ترتیب تصادفی مقادیر در ستون "ID" وارد می شوند. اما به دلیل شاخص پیش فرض خوشه ای در ستون ID ، سوابق از نظر جسمی به ترتیب صعودی مقادیر موجود در ستون "ID" ذخیره می شوند. برای بازیابی سوابق از جدول دانشجویی ، عبارت SELECT زیر را اجرا کنید.
سوابق به ترتیب زیر بازیابی می شوند:
| id | نام | جنس | لنگه | نمره کل | شهر |
| 1 | بد | زن | 1989-06-12 00: 00: 00. 000 | 500 | لندن |
| 2 | جون | نر | 1974-02-02 00: 00: 00. 000 | 545 | منچستر |
| 3 | سارا | زن | 1988-03-07 00: 00: 00. 000 | 600 | لیدز |
| 4 | ارباب | زن | 1981-12-22 00: 00: 00. 000 | 400 | لیورپول |
| 5 | الن | نر | 1993-07-29 00: 00: 00. 000 | 500 | لندن |
| 6 | کیت | زن | 1985-01-03 00: 00: 00. 000 | 500 | لیورپول |
| 7 | جوزف | نر | 1982-04-09 00: 00: 00. 000 | 643 | لندن |
| 8 | موش | نر | 1974-08-16 00: 00: 00. 000 | 543 | لیورپول |
| 9 | عاقل | نر | 1987-11-11 00: 00: 00. 000 | 499 | منچستر |
| 10 | الی | زن | 1990-10-28 00: 00: 00. 000 | 400 | لیدز |
ایجاد فهرست خوشه ای سفارشی
شما می توانید فهرست سفارشی خود و همچنین شاخص پیش فرض خوشه ای را ایجاد کنید. برای ایجاد یک شاخص خوشه ای جدید در یک جدول ، ابتدا باید شاخص قبلی را حذف کنید.
To delete an index go to “Object Explorer> Databases> Database_Name> Tables> Table_Name>ایندکس ها ". روی شاخصی که می خواهید حذف کنید کلیک راست کرده و حذف را انتخاب کنید. تصویر زیر را مشاهده کنید.

اکنون ، برای ایجاد یک فهرست خوشه ای جدید ، اسکریپت زیر را اجرا کنید:
فرایند ایجاد شاخص خوشه ای مشابه یک شاخص عادی با یک استثنا است. با شاخص خوشه ای ، باید قبل از "فهرست" از کلمه کلیدی "خوشه ای" استفاده کنید.
اسکریپت فوق یک شاخص خوشه ای با نام "IX_TBLSTUDENT_GENDER_SCORE" در جدول دانشجویی ایجاد می کند. این شاخص در ستون های "جنسیت" و "total_score" ایجاد شده است. شاخصی که در بیش از یک ستون ایجاد می شود "شاخص کامپوزیت" نامیده می شود.
فهرست فوق اول همه سوابق را به ترتیب صعودی جنسیت مرتب می کند. اگر جنسیت برای دو یا چند رکورد یکسان باشد ، سوابق به ترتیب نزولی مقادیر در ستون "total_score" خود طبقه بندی می شوند. می توانید یک شاخص خوشه ای را نیز در یک ستون ایجاد کنید. حال اگر تمام سوابق را از جدول دانشجویی انتخاب کنید ، آنها به ترتیب زیر بازیابی می شوند:
| id | نام | جنس | لنگه | نمره کل | شهر |
| 3 | سارا | زن | 1988-03-07 00: 00: 00. 000 | 600 | لیدز |
| 1 | بد | زن | 1989-06-12 00: 00: 00. 000 | 500 | لندن |
| 6 | کیت | زن | 1985-01-03 00: 00: 00. 000 | 500 | لیورپول |
| 4 | ارباب | زن | 1981-12-22 00: 00: 00. 000 | 400 | لیورپول |
| 10 | الی | زن | 1990-10-28 00: 00: 00. 000 | 400 | لیدز |
| 7 | جوزف | نر | 1982-04-09 00: 00: 00. 000 | 643 | لندن |
| 2 | جون | نر | 1974-02-02 00: 00: 00. 000 | 545 | منچستر |
| 8 | موش | نر | 1974-08-16 00: 00: 00. 000 | 543 | لیورپول |
| 5 | الن | نر | 1993-07-29 00: 00: 00. 000 | 500 | لندن |
| 9 | عاقل | نر | 1987-11-11 00: 00: 00. 000 | 499 | منچستر |
شاخص های غیر خوشه ای
یک شاخص غیر خوشه ای داده های فیزیکی را در جدول مرتب نمی کند. در حقیقت ، یک شاخص غیر خوشه ای در یک مکان ذخیره می شود و داده های جدول در مکان دیگری ذخیره می شود. این شبیه به یک کتاب درسی است که محتوای کتاب در یک مکان قرار دارد و شاخص در دیگری قرار دارد. این اجازه می دهد تا بیش از یک شاخص غیر خوشه ای در هر جدول.
ذکر این نکته حائز اهمیت است که در داخل جدول داده ها توسط یک شاخص خوشه ای طبقه بندی می شوند. با این حال ، در داخل داده های شاخص غیر خوشه ای به ترتیب مشخص ذخیره می شود. این شاخص حاوی مقادیر ستون است که روی آن شاخص ایجاد می شود و آدرس رکوردی که مقدار ستون به آن تعلق دارد.
هنگامی که یک پرس و جو در برابر ستونی که روی آن ایجاد شده است صادر می شود ، پایگاه داده ابتدا به فهرست می رود و به دنبال آدرس ردیف مربوطه در جدول است. سپس به آن آدرس ردیف می رود و مقادیر ستون دیگر را واکشی می کند. به دلیل این مرحله اضافی است که شاخص های غیر خوشه ای کندتر از شاخص های خوشه ای هستند.
ایجاد یک فهرست غیر خوشه ای
نحو برای ایجاد یک شاخص غیر خوشه ای شبیه به شاخص خوشه ای است. با این حال ، در صورت استفاده از کلمه کلیدی شاخص غیر خوشه ای "nonclustered" به جای "خوشه ای" استفاده می شود. نگاهی به فیلمنامه زیر بیندازید.
اخبار رمز ارزها...
ما را در سایت اخبار رمز ارزها دنبال می کنید
برچسب : نویسنده : منیژه سلیمی بازدید : 60
آرشیو مطالب
لینک دوستان
- کرم سفید کننده وا
- دانلود آهنگ جدید
- خرید گوشی
- فرش کاشان
- بازار اجتماعی رایج
- خرید لایسنس نود 32
- هاست ایمیل
- خرید بانه
- خرید بک لینک
- کلاه کاسکت
- موزیک باران
- دانلود آهنگ جدید
- ازن ژنراتور
- نمایندگی شیائومی مشهد
- مشاوره حقوقی تلفنی با وکیل
- کرم سفید کننده واژن
- اگهی استخدام کارپ
- دانلود فیلم
- آرشیو مطالب
- فرش مسجد
- دعا
- لیزر موهای زائد
- رنگ مو
- شارژ
خبرنامه
